
I wanted to make the claim on Monday that large parts of the 3m-word surviving Old English corpus are neglected. Large parts of the 3m-word surviving Old English corpus are neglected, but – being someone who likes to quantify things – I began wondering if there was a way to calculate how much Old English criticism has focused on the most canonical texts, like Beowulf. In the back of my mind was Andrew Goldstone and Ted Underwood’s mind-blowing distant reading of seven major literary history journals between 1887 and 2013 in ‘The Quiet Transformations of Literary Studies’, with its extraordinary visualisation of the topics that have preoccupied literary scholars in the last century:
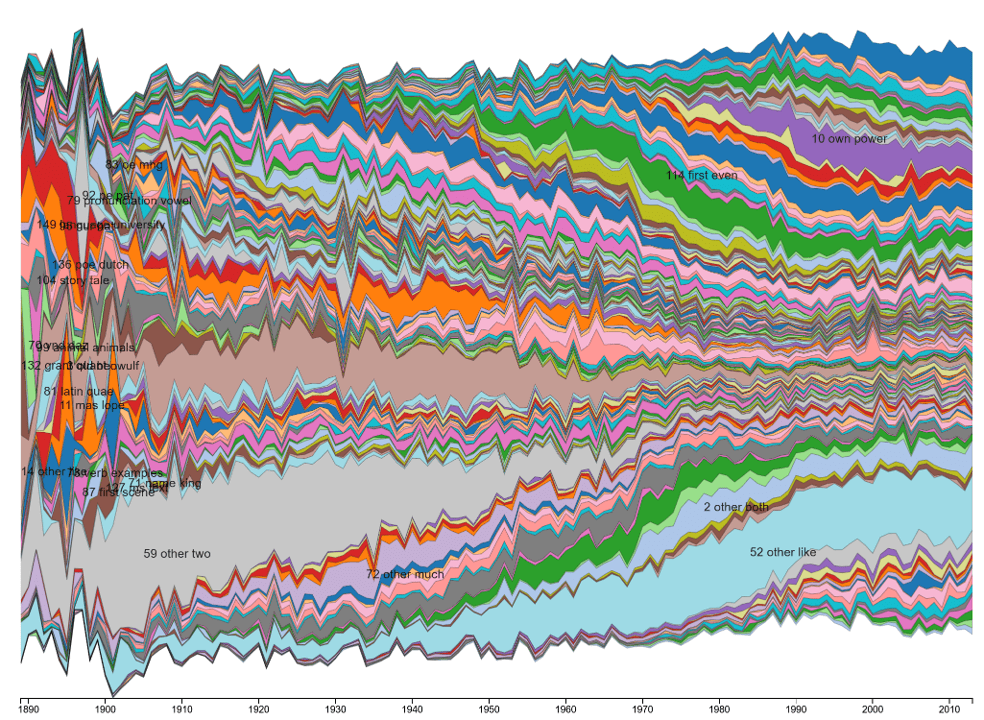
While I haven’t produced anything on a par with this, I have found a way to calculate how much Old English criticism focuses on the most canonical texts, and – incidental to that – a way to look at the disciplinary health of Old English studies relative to academia more broadly. It has also given birth to this blog – a new venue to publish things that are interesting (and I’d like to be able to cite) but which I don’t have the time to work up as fully-fledged articles.
My first idea for a dataset was the Old English Newsletter Bibliography, heroically kept online by Stephen Harris and shared by him with my PhD student, Claire, a couple of years back. But Claire had a job application to write, and the OEN Bibliography only extends to 2010, while I wanted to make a claim about present-day Old English studies. So I started playing with Brepols’ (pay-walled) International Medieval Bibliography (originally founded in 1967), and looking at how a random selection of articles on Old English had been manually indexed there. If all articles on Old English were indexed to a single overarching category, life would have been easy. Instead, articles are primarily indexed by Discipline (e. g. ‘Literature’) and Area (e. g. ‘British Isles’), and – as we all know – not all literature from the British Isles in the early Middle Ages was in English. Consequently, I decided I would need to utilise the index terms for both Subject and Persons, Families, Texts, for Subject included ‘Old English’ and Persons, Families and Texts often included text-based index terms including ‘OE’ (e. g. in ‘Maxims, OE poem’). ‘OE’ yields 4,255 hits in IMB, and ‘Old English’ 3,466. While the IMB interface has a button that says ‘Export All’, the resulting download is in fact capped at 500 entries, so I had to extract the data in batches. Because some articles were indexed with both search terms, I deduplicated on the basis of the IMB identifiers given to each item (e. g. IMB (a1137767)). That left a dataset of 6,774 publications.
This list is certainly not a complete inventory of publications on Old English between 1967 and the present day. First and foremost, the IMB until recently almost totally excluded monographs and primarily indexes articles in journals or edited collections. Presumably, too, because of the inherent difficulty of comprehensiveness, they missed some articles on Old English in obscure publications. More seriously, some publications on Old English are not indexed as either ‘OE’ or ‘Old English’. This seems to be particularly the case with prose works. For instance, of 690 publications indexed ‘Ælfric, abbot of Eynsham’, 162 (23.5%) do not contain ‘OE’ or ‘Old English’ as index terms. I should probably have searched the IMB for all known Old English author and work names, but that would be quite exhausting (and still not necessarily ensure exhaustiveness). Despite covering a narrower period (1970-2010), the OEN Bibliography is certainly more extensive than my dataset from IMB, with 23,700+ rows in the csv file Stephen shared with Claire, but it includes monographs and other publication types, and it looks like it would take a lot of work to make any kind of confident statement about its relative coverage. So I rolled with what I had.
One bit of minor data wrangling was necessary before producing any visualisations. In the IMB export, not all publications have a date in the date column; however, they are listed in (reverse) chronological order, so any publication that appears in a row between one from year XXXX and another from the same year must also be from year XXXX. Where the row was between one from year XXXX and one from YYYY, I manually verified the date. For computation purposes, I treated publications from XXXX (for YYYY) as being published in year XXXX (my thinking being that even in the case of an article published in ZZZZ, the author may in fact have submitted it five or ten years beforehand; the editors were taking some zzzzs, presumably) and publications in journal volumes for XXXX-YYYY as having been published in the later year. I also excluded any publications that were not journal articles or book chapters, given the under-representation of other publication types in IMB. This gave me raw counts of publications on Old English per year. Inspecting these results suggested IMB coverage at the extremes – 1966 and 1967 at the beginning and 2025 and 2026 at the end – is a bit patchy, so I discounted these years. I also applied some rudimentary smoothing, by averaging each year’s production across the two years before and after it. That yielded this graph:
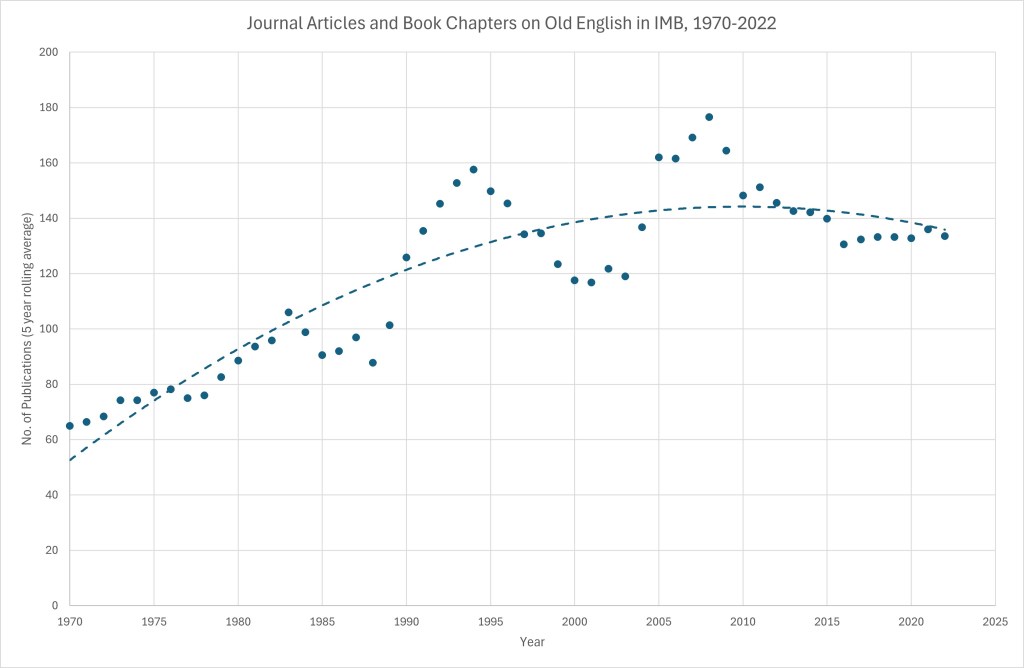
So there are about twice as many articles and book chapters being written about Old English now than there were in the 1970s: horray! Quite what explains the peaks in productivity in the mid 1990s and late 2000s, I’m not sure. We’d need to bear in mind the possibility that the peaks are not peaks in publication, but peaks in the assiduousness of the IMB’s compilers, and absent Brepols giving me the whole IMB to play with, I can’t think of a way to test that possibility.
But is the health of the discipline actually as rosy as this graph suggests? More and more journals are being established and thus, presumably, more and more articles being published (see Brian McGill’s post, ‘The State of Academic Publishing in 3 Graphs, 6 Trends, and 4 Thoughts’). There may be better datasets about total academic publications over time out there, but a brief search led me to To & Yu’s ‘Rise in Higher Education Researchers and Academic Publications’ from 2020, which utilised – inter alia – figures for total numbers of publications indexed by Scopus for the period 1980-2018, and conveniently made these available for download among the article’s supplementary materials. Applying the same rudimentary smoothing to this data yields parallel data to IMB for 1982-2016. Taking 1982 as 1 and calculating the number of articles published each year relative to that enables the datasets to be compared over time:
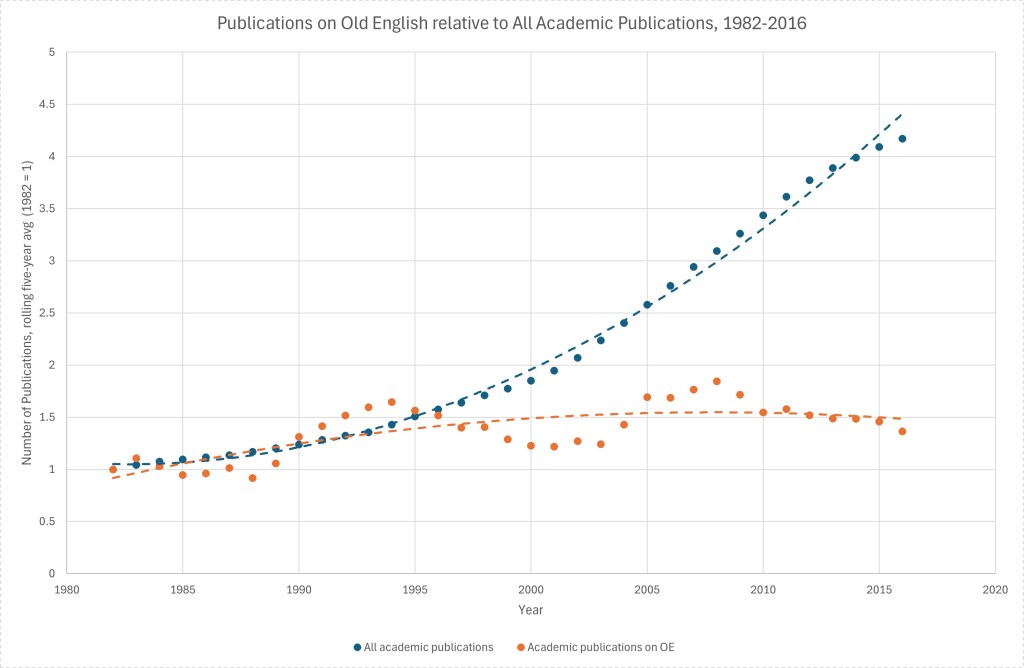
So the picture is actually not quite so rosy. The number of publications on OE has been rising over time, but it has not kept pace with overall publication trends. While in rude health to 1995, publication on Old English has remained essentially stable since then, while academic publication in general increased almost threefold in the 20 years that followed.
But what of the topics those publications on Old English have addressed? Have they changed? The ‘Export all’ function in IMB does not yield the topics under which each publication was indexed, but it does give the titles. I therefore decided to concordance these, having first deleted all non-capitalised words (as a kind of rudimentary alternative to using a stop list to discount the articles, prepositions etc that reveal nothing about a publication’s topic). That yielded a list of 4,245 words occuring between them 23,496 times in the titles of the 6,774 publications in my IMB-derived dataset. Two thirds of these are hapaxes (and have some possibility of serving as the basis for a round at the next quiz at the IMC: can you name the only article on Old English which refers to Catullus in its title?). The top 1% of title words by ranked frequency are also the only ones that occur over 20 times per 10,000 title words, and these 42 include the names of seventeen canonical Old English works and authors: Beowulf (1376 instances), [Battle of] Maldon (130), Genesis [A/B] (129),[Dream of the] Rood (124), Christ [I / II / III / & Satan] (122), Exodus (120), Ælfric (116), Andreas (99), Wanderer (83), Riddle [XX] (73), [OE] Bede (68), Guthlac [A/B] (64), Seafarer (61), Wife[’s Lament] (59), Judith (56), [King] Alfred (55) and Wulf [and Eadwacer] (51).
To see how prevalent each of these canonical works and authors has been in Old English scholarship over time, I identified the corresponding IMB Persons, Families and Texts labels for each. In some cases this was just one label, e. g. ‘Battle of Maldon, OE Poem’ but in others it was more than one, e. g. for Genesis ‘Genesis, OE Poem’, ‘Genesis, OE poem – Genesis A’ and ‘Genesis, OE Poem – Genesis B’. This yielded a list of 4,265 publications using these index terms. Having ensured each was associated by a single year, and – as with the broader OE dataset above – counting only journal articles and essays in collected volumes, and conducting the same rudimentary smoothing, we can look at what portion of the scholarship on Old English over the last fifty years has focused on Beowulf:
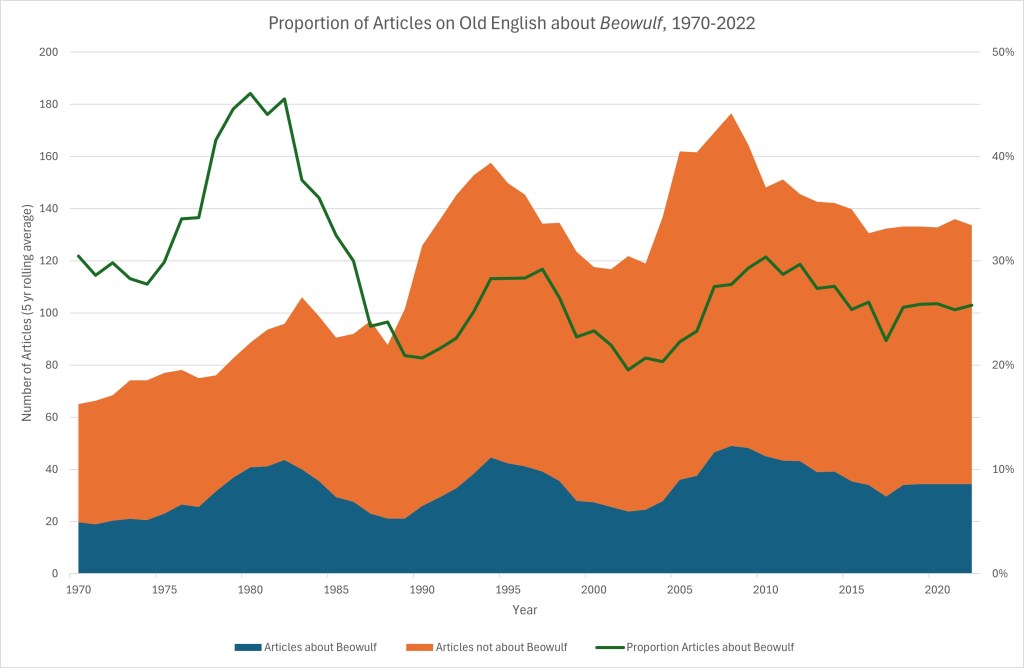
An important caveat before we interpret this graph is that articles about Beowulf are not necessarily articles exclusively about Beowulf, but rather articles which treat Beowulf to a degree significant enough for the IMB’s bibliographers to notice; they may also treat other texts. With that in mind, we can say that interest in Beowulf peaked in the early 1980s, when almost 50% of articles on Old English had something substantive to say about it. Since the late 1980s, about a quarter of published articles have been concerned with Beowulf.
But what about canonical texts tout court? I grouped the seventeen canonical texts and authors on which I collected data into prose and verse, yielding three prose (Ælfric, Alfred and the OE Bede) and fourteen verse texts. Because some articles concern multiple canonical texts, e. g. Bourquin’s ‘Lexis and Deixis of the Hero in Old English Poetry’, which discusses Andreas, Guthlac, Judith, Beowulf, Battle of Maldon, Dream of the Rood, Exodus and Christ poems – Christ indeed! – I deduplicated so each article in the dataset focused on a canonical verse text counted only once, and each article on a canonical prose text counted only once. Furthermore, because a few articles (51 to be precise) dealt with a canonical prose text and a canonical verse text, when calculating the total number of articles published per year on canonical articles, I counted these articles once only. This means that the total number of articles published on canonical texts is very occasionally less than the sum of the number of articles published on prose and on verse canonical texts (e. g. in 1976, I have 58 articles total on canonical texts, but 6 on prose and 53 on verse, because Paul Szarmach’s summary of the Old English Division meeting at the MLA for OEN treated papers that concerned both canonical prose and verse texts). Bearing that in mind, we come to my final graph:
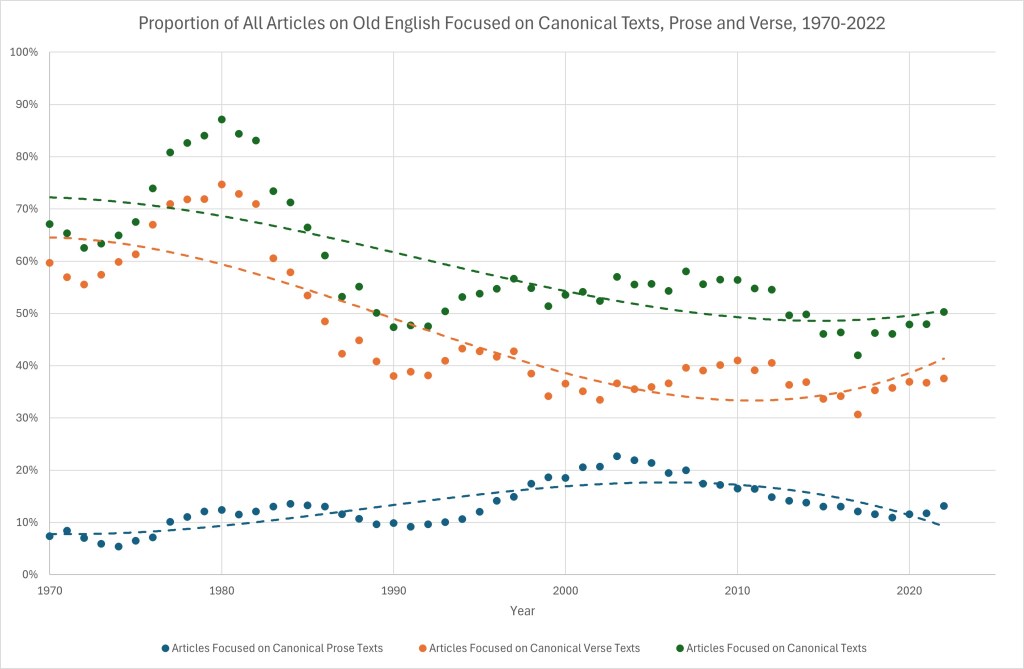
This graph suggests that the proportion of research on Old English concerned with canonical texts was, as of 2022, about 50%. That figure has remained more or less stable since the late 1980s, having peaked at nearly 90% in 1980. Scholars have been much more interested in verse than prose over the last fifty years, with canonical verse texts commanding about three times as much attention as prose texts in 2022. Interest in canonical prose texts almost tripled between the late 1970s and the early 2000s, but since then has almost halved (though there inchoate signs of an uptick since 2020).
So, to answer my own question, the IMB dataset suggests that about half of the criticism on Old English at the moment is on the seventeen most canonical texts. Or, to put it another way, over the last fifty years, 2,765 articles out of 6,352 on Old English have focused on fourteen verse texts; that is, 44% of publications on Old English have focused on 2% of the corpus by wordcount. If that’s not an incitement to go and look at one of the other 3,052 texts in DOEC, I don’t know what is.
***
There’s probably a lot more that could be done with this dataset, for instance to explore the no less than nineteen languages in which it indicates scholars have published on Old English. It is, I hope, needless to say that nothing above is intended as a criticism of anyone who works on canonical Old English texts. I well understand the pressure that working in an English department might create to focus on things that colleagues who specialise in other period might understand, like poetry (indeed, one of the few bits of advice one of my PhD supervisors gave me, when my first article (on an obscure, and probably non-existent, East Anglian saint) came out, was to try to publish something on something canonical soon so I’d be comprehensible on the job market). The aim of the article is rather to hold a mirror up to what we publish on, without opining (too much) about whether that is right or wrong. If anyone would be interested in collaborating to write this up properly, let me know and I’m happy to share the provisional data.
